|
Introduction Components |
Multisearch LogThese are the log files from 16 - 20 June 2008. For additional log files, please return to the main log page. Friday, 20 June Thursday, 19 June I'm currently reading up on Hadoop's File System and Map/Reduce Tutorial, learning about redundancy and replication. I went to the library yesterday and pulled a few books that include Web 2.0 programming, too, and I'll be looking at what kind of Web Services/Applications I'm likely to run into. This way, I can see if there are any common denominators (not just XML) and see if I can make a modular way of working with them. Axis Services are very popular, and I've worked with them before. The first step for me is to launch a Lucene Service on one of the servers, probably Pileus, using the ONJava Tutorial, which is, incidently, the same one I used in 2006 to develop Multisearch! Pileus wasn't happy for a while, but I think I've managed to fix it. I think there needs to be a significant wait when Tomcat is restarted for the OGSA-DAI backends to load on Pileus and Snowy (in the realm of 2 minutes for Pileus and perhaps 5 minutes for Snowy). Now Pileus has a LuceneAxisService on it, which I will launch very soon. I am thinking of leaving up some of the OGSA-DAI services after the results are complete for TREC, which looks to be Friday. That'll be good testing for Hadoop/Multisearch. I'm going over the Word Count Example for Hadoop, and from this example I'll need to know the following for the code:
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> With Map, we'll need to figure out something where the Value is the Query, and the Key is the hash of that Query. During the Map, we need some sort of method of assigning nodes on possibly other servers for backends. I'm not quite sure how this will be done yet.
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> This looks much more promising! With the key, we can take the values (which will be Document, Rank pairs) and merge them together. It might be necessary to remove the Query key, as given we know we're running the same query, and have the key be a hash of the document somehow. Merging them together will have to be modular, since we'll want to be able to decide how it's done. I might have to write multiple reduce functions, we'll see.
public static void main(String args[]) This is really simple, but all the work behind it (writing the classes) might be messy... IMPORTANT: On Snowy, I added "-Xmx3500s -Xmx3500m" to catalina.sh, meaning Tomcat MUST use 3500m when started... Wednesday, 18 June I know I loaded some of the new code onto Snowy because I wanted to see if I could run Nimbus and Snowy at the same time, one generating lsi150dyn and the other vsmdyn. It didn't work, so I let Nimbus continue with lsi150dyn. I overwrote a lot of the Multisearch java code from last year, but not without backing it up in a .tar file. I untarred that file and reverted Snowy to the older code. - #1213814664654:0# Activity output ogsadai-11a9cfd4c7b has no data to be accessed. This only happens when there is NO appropriate XML packaged, meaning snowy is not even returning the right information. I checked Snowy's log files for OGSA-DAI, and here is what I've found:
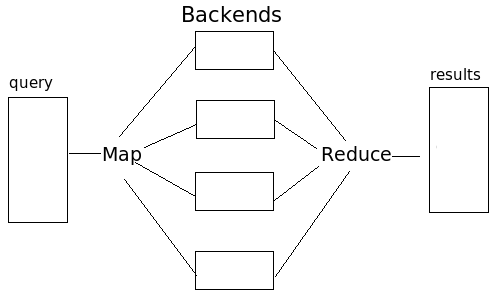
153387 [Thread-35] ERROR uk.org.ogsadai.activity.ResponseDocumentBuilder - #1213745339388:14# A server-side error occurred. I dropped a .jar file (LuceneAccessor.jar) into $CATALINA_HOME/webapps/axis/WEB-INF/lib, worried I hadn't dropped the right version in before. I restarted Snowy while Nimbus was still running the search--and it worked. Snowy loaded the searches right away! So I stopped the searching and loaded it up again. It wasn't the jar file that helped. I was getting no packages again! So I stopped Snowy again and restarted it. It works! I'm not sure why... Update: Right before lunch, Greg and I looked at the memory errors on Snowy. He added a JAVA_OPTS addition to catalina.sh and it seems to have worked out on Snowy. I'm running hte results now, although they're taking 2-3x longer than the other sets were before. Most of the work I've been doing with Hadoop is working with the architecture and such, thus producing a new architecture for Multisearch:
Hadoop uses Map to coordinate what is run where. The results are gathered by an output gatherer and sent to at least one reducer, which combines similar keys. This is great for Multisearch! Some things to be kept in mind:
Since vsmdyn is still running, I can't upgrade Tomcat. I'm going to grab some books on AJAX and some other Web 2.0 things (they might be helpful with different TYPES of backends...) to work with the design there. I might keep some of the OGSA-DAI backends to see if we can have Axis Services, Web 2.0 Services, and something like OGSA-DAI all work together... I want to see how flexible the code would need to be to do all that. Tuesday, 17 June I checked the OGSA-DAI logs, and I found that it cannot package more information without giving a memory error, so it's justJavaTM 1.5.x, preferably from Sun, must be installed. sending back empty packages! I'm not sure how to fix this... I'll be running more tests to figure out what the problem is. I editted Snowy's $CATALINA_HOME/bin/catalina.sh file, adding -Xmx1028m to JAVA_OPTS to try to improve the memory problem, but it hasn't done much. I asked Greg to look into it, and he logged in as me and found this error: Exception in thread "main" java.lang.ClassFormatError: edu.arsc.multisearch.DynamicRun (unrecognized class file version) Monday, 16 June I met with Greg to talk about reimplimenting Multisearch with Hadoop instead of OGSA-DAI. He also said I should keep track of their differences (ease of implementation, run time, etc.) because we might write a paper on it. Right now, for Multisearch, it looks like the Mapper function will be running searches on different backends and the Reducer would be combining the results. What Hadoop/Nutch does right now is distribute the searching from ONE index, but our goal is to have multiple indexes. We also want to assume the least possible amount about the systems that we're working with – and we want an automatic way of dealing with backends. My idea is to have the servers provide a file (we'll say uri/path/filename.txt for example) where all the backends are listed to be grabbed. This way we just need to check the servers and those files and do nothing by hand, eh? In addition, it would be nice of Hadoop wasn't based on Tomcat, if at all possible, since we want to assume as little as possible. I think what I might do is build things with AJAX, since I want to learn that, too. After the TREC results are run, I am hoping to be able to upgrade everything, from Lucene to Tomcat. Since I'm building with new software, I might as well start afresh with new software. |

Arctic Region Supercomputing Center © Arctic Region Supercomputing Center 2006-2008. This page was last updated on 23 June 2008. |
|