|
Introduction Components |
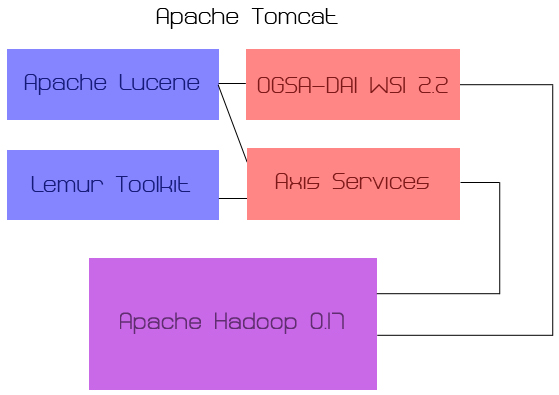
Software Components of MultisearchIntroduction Two information retrieval packages were used: Lemur and Lucene. These were used to generate the indexes to be searched. Axis services and OGSA-DAI were both used to generate backend services. Technically, OGSA-DAI uses Axis to launch services, but the user doesn't deal directly with Axis. These services all interact with Hadoop.
Tomcat $CATALINA_HOME Tomcat allows web services, both front-ends (where the client interacts with the software) and the backends (where the services run the query and return the results). Axis Services & OGSA-DAI OGSA-DAI was originally incorporated into Multisearch in 2007, when the variation was OGSA-DAI WSI 2.2 It is a middleware that provides a structure for grid computing services. OGSA-DAI is great for people or groups that want to launch multiple backends quickly in a structured environment. OGSA-DAI uses Axis to do this. However, Axis services can be created by users as well. Multisearch 2006 used Axis services for backends. Now Multisearch 2008 can use both the structured OGSA-DAI backends and the other Axis services generated. Axis services are good for users/groups that want more flexibility in programming, especially with fewer backend services. Lemur Lucene Hadoop Hadoop uses a map() function to take a set of <key, value> pairs and maps them to be run at the same time. The map() function produces an intermediate set of <key, value> pairs (not necessarily of the same type) which are then passed to the reduce() function. The reduce() function takes values with the same key and groups them together. Multisearch uses Hadoop to run its distributed searching. At the map() phase, it creates clients to connect to the backend services, using <query, ServiceWritable>. The clients return ResultSets, which are then outputted by the map() function as <query, ResultSetWritable> values. The reduce() function merges all the ResultSets together by rescoring and reordering the documents in the ResultSets passed to it by the mapper. |

Arctic Region Supercomputing Center © Arctic Region Supercomputing Center 2006-2008. This page was last updated on 12 August 2008. |
|